让 Claude Code 或 Codex 改一个稍大点的项目,它常常满屏 grep、反复打开文件、读了又读。这就像一个刚到陌生城市的人,没有地图,只能挨条街走过去问路:慢、费劲,还容易走错。
codegraph 做的事,就是先把你的代码库测绘成一张地图,再交给 AI 这位「副驾驶」当导航用。 地图归 codegraph:函数、类、变量是一个个「地点」,谁调用谁、谁定义在哪是连接它们的「道路」;导航归副驾驶(下文都这么叫这位 AI):它拿着地图规划「改哪个函数、沿哪条调用链会波及谁」。
接上之后最直接的好处是 AI 不再瞎逛——省 token、找得更准、回答更快。 按官方实测(7 个开源项目对比开/关 codegraph,2026-05 复测):平均约省 25% 成本、少用 57% token、快 23%、减少 62% 工具调用。
要理解它为什么能省这么多,先看清 grep 卡在哪。
一、grep 解决不了的问题:只认「字」,不认「路」
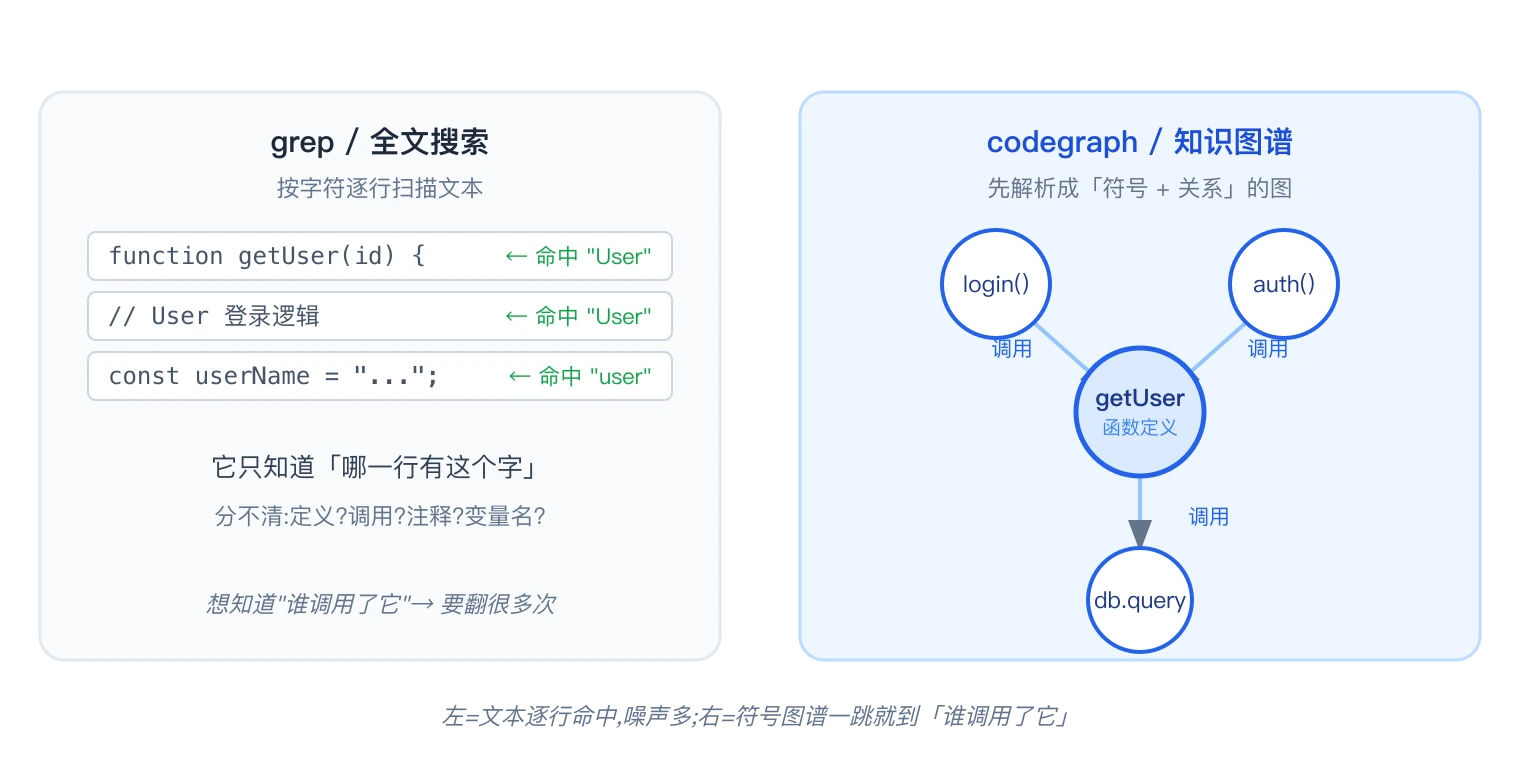
来看一个最常见的需求:想知道 getUser 这个函数被谁调用了。
你 grep getUser,命中几十行:函数定义有它、注释有它、同名变量 getUserName 有它、日志字符串也有它。grep 只回答一个问题:「哪一行文本里有这串字符」,它看字面,不看含义。
codegraph 换了个思路:先用 Tree-sitter(一个高性能的代码解析库)把代码解析成 AST,从中抽出符号(函数 / 类 / 变量)和调用关系(谁调用谁、谁定义在哪),存成一张知识图谱——这就是那张「地图」,地点用道路连成的网。图谱落在一个纯本地、不联网的单文件 SQLite 里,查询不走网络,亚毫秒返回。
 所以两者各管一摊,谁也替不了谁:
所以两者各管一摊,谁也替不了谁:
| 问题 | 用什么 |
|---|---|
「哪行日志里写了 connection timeout」 | grep / 全文搜索(擅长字面文本) |
「getUser 定义在哪」 | codegraph |
「谁调用了 getUser」 | codegraph |
「改了 getUser 会影响什么」 | codegraph |
「getUser 的签名长什么样」 | codegraph |
二、它不是语义搜索,却能帮 Claude 精准找代码
codegraph 听不懂「登录逻辑」这种人话,找口述的逻辑这一步不归 codegraph 管,是副驾驶干的活。
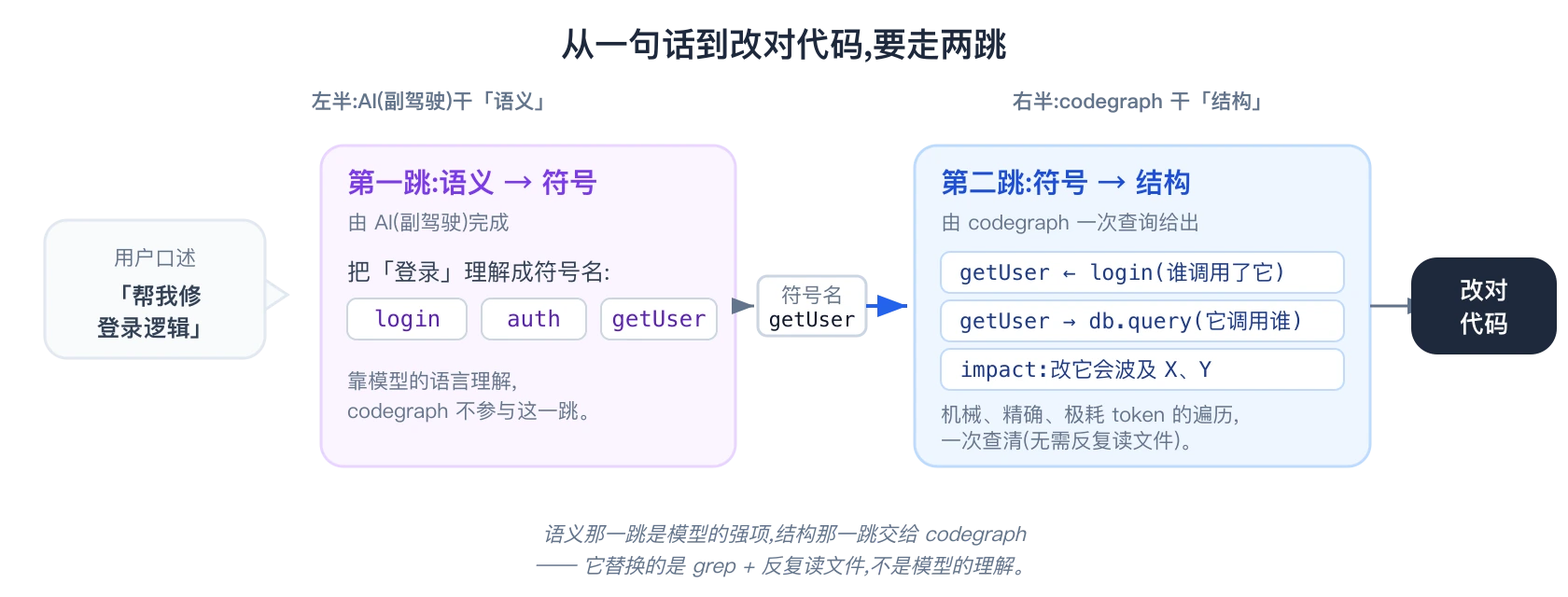 第一跳:语义 → 符号(副驾驶干)。 「帮我修登录逻辑」,AI 把「登录」映射到
第一跳:语义 → 符号(副驾驶干)。 「帮我修登录逻辑」,AI 把「登录」映射到 login、auth、getUser 这些符号名。这一步靠模型,codegraph 不参与。
第二跳:符号 → 结构(codegraph 干)。 拿到符号名,「谁调用它、它调用谁、改动波及哪里、完整调用链」这些遍历机械、精确,但极耗 token。让模型自己 grep + 反复读文件去拼,既慢又贵;交给 codegraph,一次查询就给齐。
所以 codegraph 是 AI 的「结构导航仪」:它替掉「grep + 反复读文件」这个又笨又贵的环节,不碰模型的语义理解。副驾驶听懂人话,codegraph 把静态结构里的路一次认清,两者各管一跳。
三、2 分钟拿到第一张地图
第一步:装 CLI。
# macOS / Linux(安装脚本自带运行时,无需先装 Node)
curl -fsSL https://raw.githubusercontent.com/colbymchenry/codegraph/main/install.sh | sh
# Windows(PowerShell,同样自带运行时)
irm https://raw.githubusercontent.com/colbymchenry/codegraph/main/install.ps1 | iex
# 已有 Node 环境,也可以直接 npm 全局安装
npm i -g @colbymchenry/codegraph
第二步:接进 AI。 装好 CLI 还不够——得跑 codegraph install 把 codegraph 注册成 MCP 服务,Claude Code / Codex 才知道有它可用:
codegraph install # 交互式,选择给哪些 CLI 安装并配好
第三步:进项目,建初始索引(第一次测绘地图)。
cd 你的项目
codegraph init # -i 在初始化的同时建好索引
第四步:验证三连,确认地图画好了。
codegraph status # 索引是否健康、符号数 / 文件数
codegraph query User # 按名字搜符号,验证图谱能查
codegraph files # 看项目文件结构
四、地图会不会过期:三层刷新机制
刚改完代码,CodeGraph 的图谱能及时同步嘛?
CodeGraph 的代码图谱是一份会刷新的快照,是离线地图而非实时卫星图,但它靠三层机制不断更新,从「最重」到「最轻」依次是全量重建 → 自动监听 → Git 钩子兜底。一张表看清什么时候用哪层:

| 你处在什么场景 | 用哪一层 | 要手敲命令吗 |
|---|---|---|
| 第一次 / 怀疑地图坏了 | codegraph init 或 index --force(全量重建) | 要 |
| 日常写代码、让 AI 查(开着 MCP 服务) | 自动监听器(自动增量) | 不用 |
| WSL / 监听失灵 | Git 钩子里 sync --quiet(兜底) | 配一次 |
记住一件事:自动监听有延迟,存盘后不会立刻生效——它有个 2 秒的防抖窗口,连续保存还会顺延,加上写库耗时,实际等待往往比 2 秒更久。
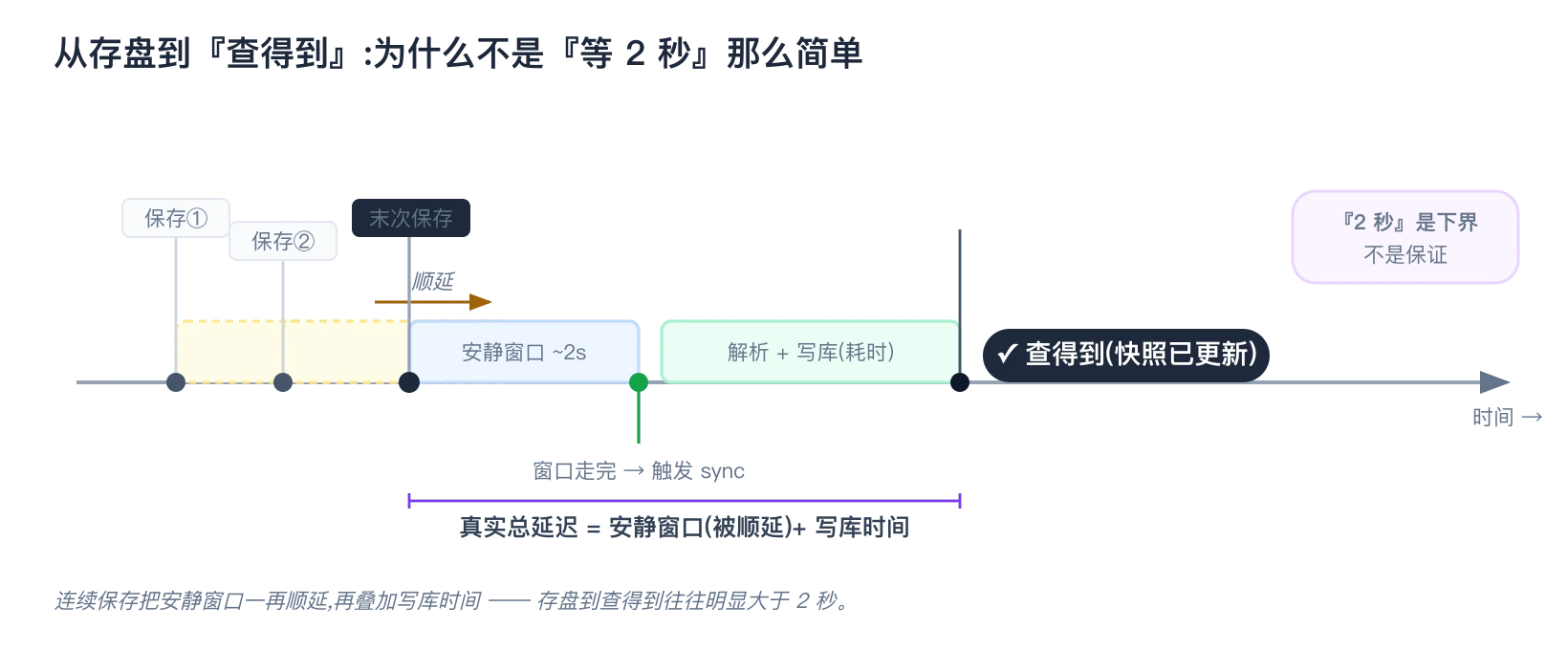 但让 AI 用的时候你基本不用操心:AI 一轮对话本身就要好几秒,等它真去查 codegraph,你那次保存的防抖窗口早过完了。真正会让地图落后的是另一种情况——监听器没生效(WSL 慢盘、或没开 MCP 服务),这时靠第三层的 Git 钩子兜底:
但让 AI 用的时候你基本不用操心:AI 一轮对话本身就要好几秒,等它真去查 codegraph,你那次保存的防抖窗口早过完了。真正会让地图落后的是另一种情况——监听器没生效(WSL 慢盘、或没开 MCP 服务),这时靠第三层的 Git 钩子兜底:
# .git/hooks/post-commit —— 每次提交后增量同步,监听失灵也不丢更新
codegraph sync --quiet
sync是增量同步,基于文件系统判断哪些文件变了(不依赖git status),所以git pull、切分支、编辑器之外的改动都能被它发现。CI 里还能配codegraph affected只跑受影响的测试。这些进阶细节、以及防抖调参的环境变量CODEGRAPH_WATCH_DEBOUNCE_MS,需要时查官方文档即可。
五、地图也有画不出的地方:三类失效场景
地图给出"不准"的结果,只有三类来源:
- 时效滞后:快照没追上改动,就是上一节那个延迟。日常让 AI 用基本不会撞上,监听失灵的环境靠 Git 钩子兜底。
- 未初始化:没建过快照,MCP 工具直接报
not initialized,codegraph init -i建出来即可。 - 结构盲区:它只懂结构、不懂语义,答得了「谁调用了
getUser」,答不了「哪段在处理登录」(后者是语义,归 AI)。另外,回调、反射、依赖注入这类运行时才确定的调用,纯静态分析画不出——不过最新版 codegraph 已对 React、Spring 等常见框架做了专门桥接,只有遇到没覆盖的写法才会断链,断链处回源码确认即可。
六、副驾驶拿到了哪些工具
codegraph install 已经把地图交给副驾驶了。这一节看 AI 实际能用上哪些工具——以及 install 想脚本化时的进阶写法。
写进 CI / 脚本、想跳过交互时,用参数一把装好:
codegraph install --target=claude --location=global --yes
装好后 AI 就能通过 MCP 调用 codegraph 的一组工具。

| 工具 | 干什么 |
|---|---|
codegraph_explore | 首选入口:一次返回相关符号的逐字源码 + 调用流,还附影响半径(Blast radius)——谁依赖它 + 哪些测试覆盖它 |
codegraph_search | 按名字找符号 |
codegraph_callers / codegraph_callees | 谁调用 X / X 调用谁 |
codegraph_impact | 改 X 会影响什么 |
codegraph_node | 看某符号的签名 / 源码 |
codegraph_files | 看项目文件结构 |
codegraph_status | 看索引状态 |
提醒一句:老版本里独立的 codegraph_trace(看调用路径)和 codegraph_context(给任务上下文),v0.9.9 起已并入 codegraph_explore——现在 explore 一个工具就把「源码 + 调用流 + 影响面」全给齐。旧版可能仍能看到这两个,一切以你本机 codegraph --help 和实际 MCP 工具列表为准,别照搬任何教程(包括这篇)里写死的工具名。
七、codegraph vs fast-context vs Auggie MCP
「帮 AI 找代码」的工具不止 codegraph 一个,它们表面干同一件事,底层机制却分两派:结构 vs 语义。

三者解决的不是同一类问题。*
| 维度 | codegraph | fast-context | Auggie(Augment) |
|---|---|---|---|
| 机制 | Tree-sitter → AST 知识图谱 | 目录树 + 问题发给 Windsurf 的 Devstral 模型现场检索 | 专有语义 Context Engine |
| 擅长 | 结构 / 影响面,精确 | 语义检索 | 语义 / 跨仓库检索 |
| 数据位置 | 纯本地 SQLite | 需联网、需 API key | 商业云端 |
| 更新 | 增量 | 现场检索 | 云端 |
| 规模 / 成本 | 免费开源 | —— | 可扩 40 万+ 文件,商业付费 |
怎么选,看你要回答的是哪类问题:
- 想确定地、可离线、零成本地回答「谁调用谁、改这个会破坏什么」这类结构 / 影响面问题 → codegraph;
- 想用自然语言「找处理登录的代码」做语义检索,且不介意联网 → fast-context;
- 超大代码库要最强语义、愿意付费上云 → Auggie。
它们可以并存:结构问题用 codegraph,语义检索用另两个。
小结
导航准不准,先取决于地图新不新,这是本文花最大篇幅讲刷新机制的原因。几条要点:
- 它是 AI 的结构导航仪:把代码解析成知识图谱,替掉「grep + 反复读文件」,回答 grep 答不了的结构问题(谁调用谁 / 改了影响谁),纯本地、查询快。
- 两跳分工:口述意图 → 符号名由 AI 完成;符号 → 调用关系 / 影响面交给 codegraph。
- 三层刷新:初次全量 → 监听器自动增量(有延迟、非瞬时)→ Git 钩子兜底。日常让 AI 用不必操心延迟(它一轮对话就好几秒,防抖早过了);只有监听器没生效(WSL、没开服务)才靠钩子兜底。
- 三类不准:时效滞后、未初始化、结构盲区(动态分发已桥接常见框架,断链处回源码)。
- 接入用
codegraph install,日常首选codegraph_explore;选型:结构 / 离线 → codegraph,语义检索 → fast-context / Auggie,可并存。
项目地址
- CodeGraph —— GitHub: https://github.com/colbymchenry/codegraph · 文档: https://colbymchenry.github.io/codegraph/ · npm:
@colbymchenry/codegraph - fast-context-mcp(语义检索,基于 Windsurf)—— https://github.com/SammySnake-d/fast-context-mcp
- Auggie / Augment CLI(商业语义引擎)—— https://docs.augmentcode.com/cli/overview