【开源推荐】Trellis:一套让 Claude Code 如有神助的工作流
Trellis 如何通过 Hook 机制和分层 Spec 解决 Claude Code 的上下文不足、指令不稳定问题。涵盖四 Agent 调度、Research、并行开发
前言
隔三差五就能在群里看到有人问:"Claude Code有没有什么最佳实践?怎么让它别乱改我代码?"
说实话,我用Claude Code快一年了,各种框架、提示词方案试了个遍,一直没办法打包票说"有的兄弟,有的"——直到前阵子群友甩了个叫Trellis的东西给我,折腾了两周,我觉得可以聊聊了。
不是天阶功法,但确实解决了我几个很具体的痛点。
裸用模型的天花板
先说背景。今年A社模型降智说与老生常谈了,这事大家都有体感,但真正让我动摇的是三个老问题:
默认200K上下文,听着够用,实际不够。 一个中型项目,光是把核心模块的代码喂进去,上下文就吃掉大半。你还想让它理解业务逻辑?还想让它记住你之前说的约定。
压缩后不可控。 长会话到后面,Claude会自动压缩上下文。压缩完它就像喝了假酒,之前说好的代码规范、目录结构约定,全忘了,开始到处乱改。
指令遵循不稳定。 你在CLAUDE.md里写得清清楚楚"不要修改tests目录",它大部分时候听话,偶尔就是要给你来一下。
所以GPT-5.2出来后我使用后就基本切过去了。400K上下文确实大,推理能力也强,但输出慢,语言风格太"学术"——代码注释像论文摘要,每次都要"中译中"也是实打实的痛点
Trellis不是又一个CLAUDE.md
我之前也写过很长的 CLAUDE.md,把前端命名规范、后端API约定、数据库迁移规则全堆在一起,也用过各种全局Skill,效果时灵时不灵。Trellis跟这些方案的本质区别在于:
它不是一份提示词,是一套项目级的workflow + toolkit,通过Hook强制注入到每次会话里。
关键词是"强制"。Skill是可选的,AI心情好就用,心情不好就跳过,你拿它没办法。Trellis用了三层Hook拦截机制——会话启动时注入项目上下文,派发子Agent时注入精准Spec,Agent完成时强制质量验证。不是"你可以参考",是"你必须遵守"。
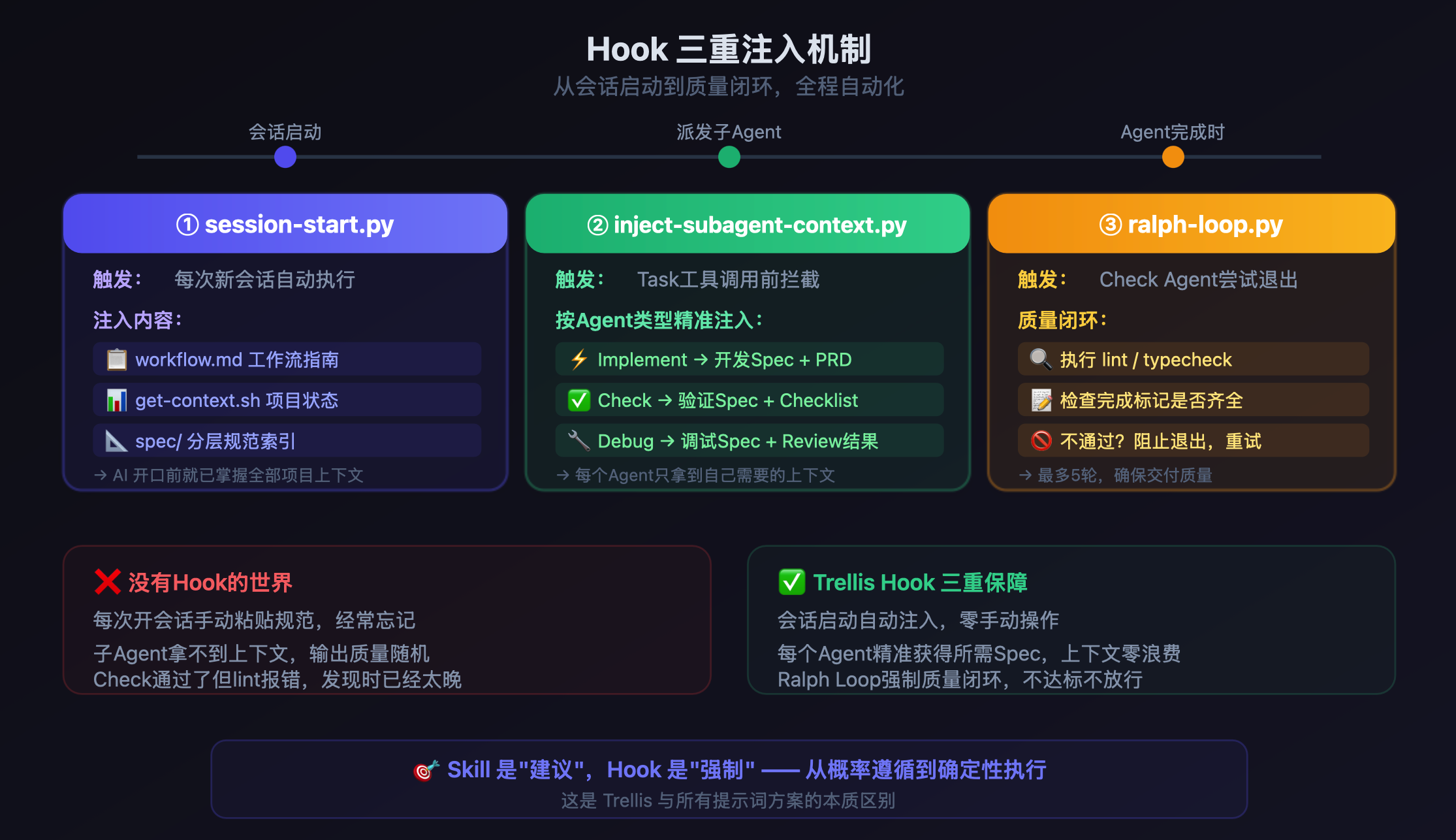
这三层Hook各司其职:
session-start.py— 每次新会话自动注入workflow和项目状态inject-subagent-context.py— 派发子Agent前,按类型精准注入对应Specralph-loop.py— Check Agent想退出时拦截,lint/typecheck不过就不让走,最多重试5轮
核心哲学一句话概括:Specs are injected, not remembered。
这套机制最优雅的地方在于——Dispatch Agent自己完全不读Spec,它只负责路由。所有上下文由Hook在幕后自动注入给对应的执行Agent。上下文零浪费,每个Agent只拿到自己需要的东西。
而且所有配置都在项目的 .trellis/ 和 .claude/ 目录下,不碰你的全局配置。换个项目就是另一套规范,干干净净。
真正打动我的三个设计
分层Spec按需加载
这个设计直接对应上下文不够用的问题。
Trellis的做法是在 .trellis/spec/ 下面按类别拆分规范文件。AI接到任务后,根据任务类型只加载相关的Spec,不相关的根本不进上下文。
举个例子,一个典型的Spec目录长这样:
.trellis/spec/
frontend/
component-naming.md # React组件命名与目录规范
state-management.md # 状态管理约定
hook-patterns.md # 自定义Hook编写规范
backend/
api-conventions.md # RESTful接口设计规范
error-handling.md # 错误处理与日志规范
guides/
git-workflow.md # 分支与提交规范
testing-strategy.md # 测试策略
改前端组件时只加载 frontend/ 下的Spec,写后端接口时只加载 backend/。听起来简单对吧?但自己搞你得写一堆条件判断逻辑,还得维护加载规则。Trellis把这套东西标准化了,省心。

在我的项目里实测下来,可用上下文大概多出了三四成。这个差距在长会话里非常明显——以前聊到第15轮左右就开始犯糊涂,现在能撑到25轮以上还保持清醒。
四Agent调度 + 会话持久化
这个对应的是"压缩后不可控"。
Trellis定义了四个核心Agent,加上Debug和Research两个按需调用的辅助角色,核心流转是这样的:
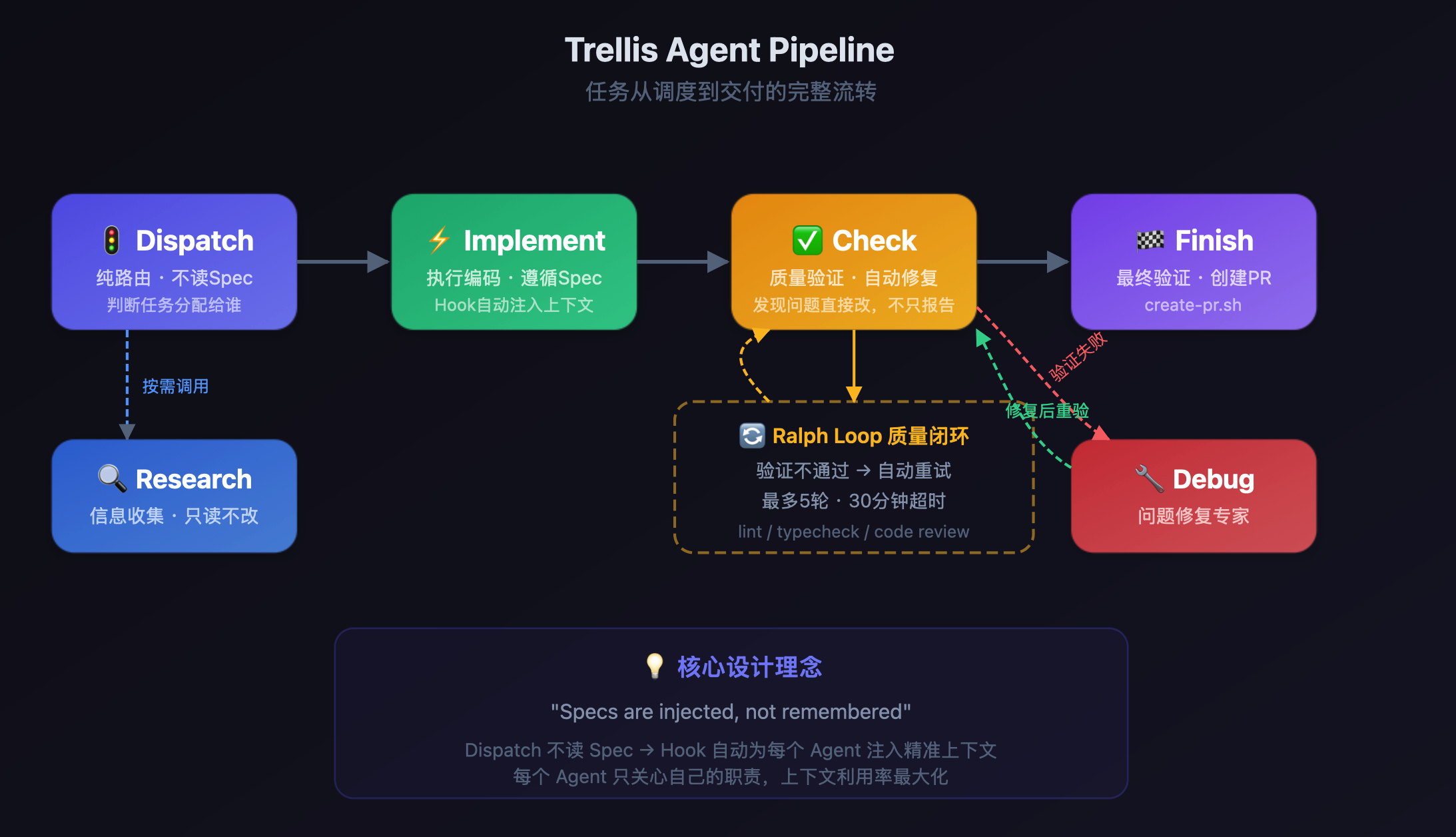
实际跑起来的感受是——每个Agent都很"专注"。
- Dispatch很轻,纯路由,判断完任务该谁干就走人,自己不读任何Spec,不消耗额外上下文。
- Implement拿到的是Hook精准注入的开发Spec和PRD,不用在一堆无关信息里找重点。
- Check不只是报告问题,它会直接动手改代码,改完跑lint和typecheck,不通过就被Ralph Loop拦住继续改,最多5轮。
- Research负责技术调研,遇到不确定的方案先查再动手。
与其让一个巨大的单体处理所有事情,不如拆成职责单一的小单元。每个Agent的上下文窗口利用率都拉满了,因为它只装自己需要的东西。
更关键的是会话持久化。Trellis会把每次会话的关键信息写进journal文件,配合git历史,下次开新会话时能把上下文接回来。不是那种"把整个聊天记录塞回去"的笨办法,是结构化的摘要和决策记录。
实际体验:以前第二天打开项目,得花10分钟跟Claude重新解释"我们昨天做到哪了"。现在基本上接着干就行。
/trellis:start 和 /trellis:parallel — 两种工作模式
Trellis提供了两种核心工作模式,覆盖从日常开发到多功能并行的所有场景:
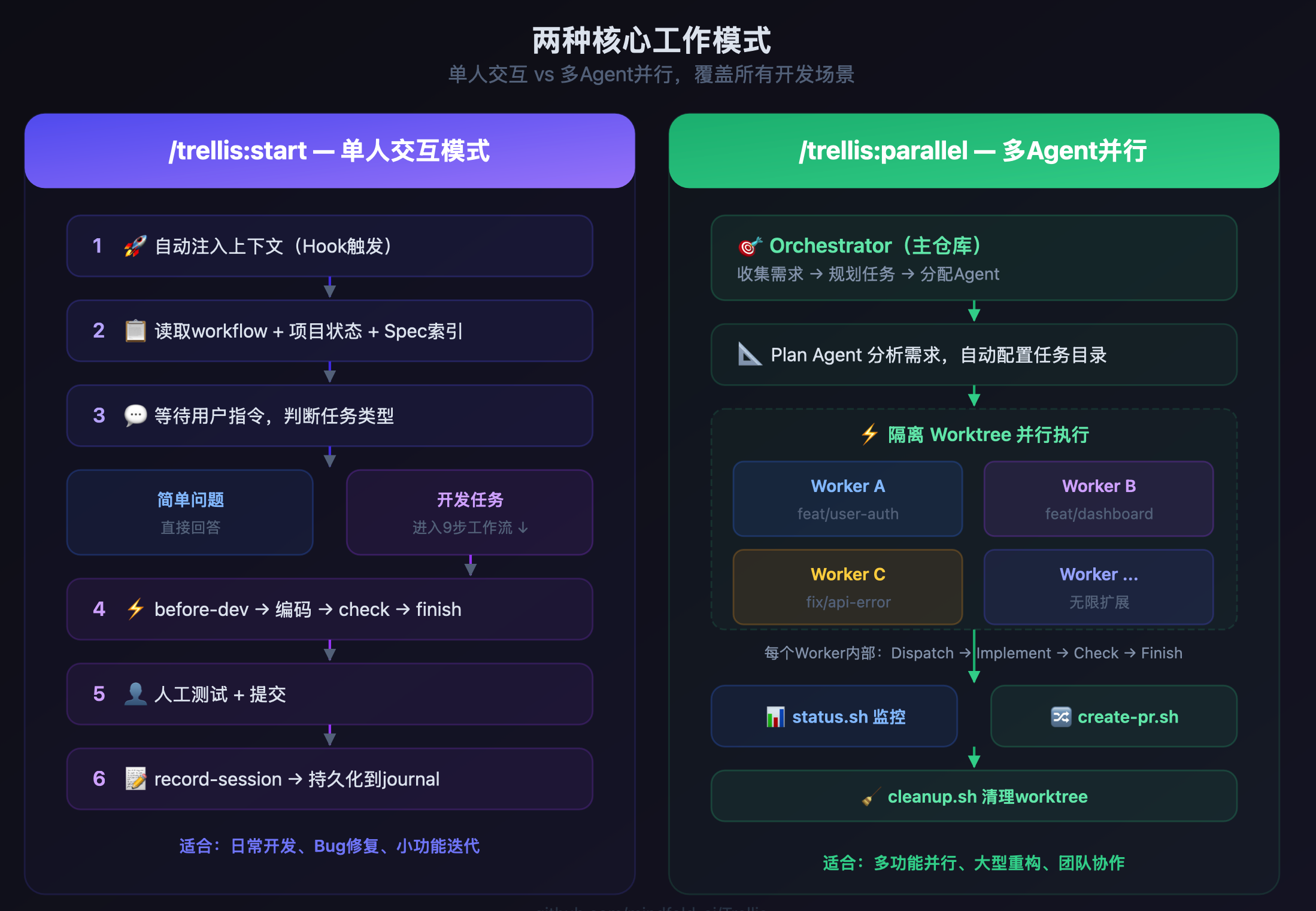
/trellis:start 是日常主力。 每次开新会话,Hook自动注入项目上下文、workflow指南和Spec索引。你说需求,它判断是简单问题还是开发任务——简单的直接答,复杂的进入结构化工作流:需求理解 → 调研分析 → PRD编写 → 编码实现 → Check验证。整个过程有章法,不是想到哪写到哪。
/trellis:parallel 是效率倍增器。 以前用Claude Code,一个会话只能干一件事,想并行就互相踩文件。parallel模式在隔离的git worktree里给每个任务分配独立的Agent,互不干扰。一个Orchestrator在主仓库统筹规划,多个Worker在各自的worktree里并行执行,改完用 create-pr.sh 直接出PR。
我现在的日常工作流:一个Worker改API,一个写前端组件,一个补测试,三条线同时推进。用 status.sh 随时看进度,哪个先完成就先review。以前一个下午能完成的量,现在上午就差不多了。
除了这两个核心命令,还有几个值得一提的辅助命令:
| 命令 | 用途 |
|---|---|
/trellis:before-frontend-dev | 写前端前自动注入组件/Hook/状态管理规范 |
/trellis:before-backend-dev | 写后端前自动注入数据库/错误处理/日志规范 |
/trellis:break-loop | 深度Bug分析,找根因而不是打补丁 |
/trellis:update-spec | 把踩过的坑沉淀成Spec,越用越聪明 |
/trellis:update-spec 这个设计我特别喜欢——每次修Bug或发现新模式,随手一条命令就能把经验沉淀到Spec库里。下次遇到同类问题,AI自动就知道怎么处理。团队里一个人踩的坑,所有人都能受益。
5分钟上手
安装和初始化就两行:
npm install -g @mindfoldhq/trellis@latest
trellis init -u your-name
跑完 trellis init 会在项目根目录生成 .trellis/ 和 .claude/ 目录结构,包括Hook脚本、默认Spec模板和Agent配置。
试错成本基本为零——不喜欢就删掉这两个目录,项目恢复原样,没有任何副作用。
Spec库值得一提:社区有现成的Spec模板可以直接拉取,React项目、Node后端、Python项目都有对应的规范集。比如React项目的模板包含组件命名、Hook使用、状态管理三类规范,clone下来改改项目名就能跑。
写在最后
用了两周,现在如果有人问Claude Code的社区的一些工具究竟有没有官方强
我现在可以比较有底气地说:有的兄弟,有的。
不是银弹,但确实是我目前找到的、能把Claude Code从"能用"拉到"好用"的最实在的方案。
如果你也在用Claude Code,欢迎加入企鹅群: 1043969119 聊聊你的工作流方案——不管是Trellis还是其他路子,互相抄作业才是正经事。